1. 是什么,有什么作用
上一篇文章说到redis是帮数据库提供一个帮手以便快速查询数据,提高数据的效率和安全性。而kafka他也是用来处理信息的信息队列,但是他主要作用在通过优化信息来处理请求上。
2. 基础架构
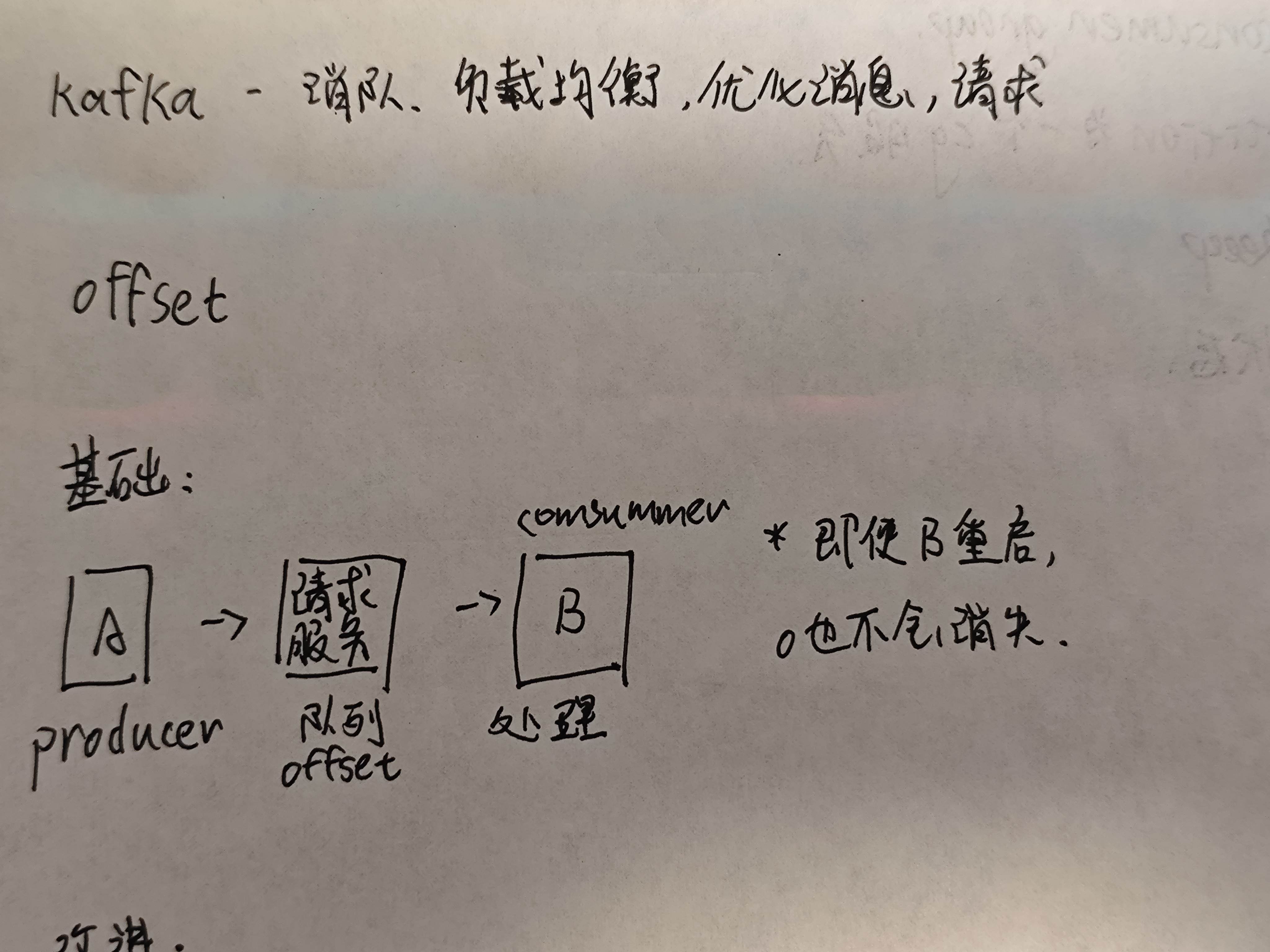 我们把kafka的队列安放在producer(新消息发出者)和comsummer(消息处理者)之间。
我们把kafka的队列安放在producer(新消息发出者)和comsummer(消息处理者)之间。
3. 改进
1. 性能
根据上边说的,kafka的消息队列目前还是掺杂在一起的粥,这样不方便commsummer处理信息请求。因此,我们引入了topic的概念。
根据不同的性质,信息会被归进不同的topic中。归入topic的信息顺序被称之为offset,他们会从 0 开始,随着消息的追加而递增。例如,分区中第一条消息的 offset 是 0,第二条是 1。它标识了该分区中消息的顺序位置,是每条信息连续且唯一的编号。
而后,假设一个topic的信息太多,一台机器可能处理不过来,因此我们把topic拆分成若干个partition(就像一个大蛋糕吃不下,但是我们可以切成小块分给别人),这样也能提高信息的处理效率。 存放数据的机器我们可以称之为broker,多个broker能够缓解单台broker的性能压力。 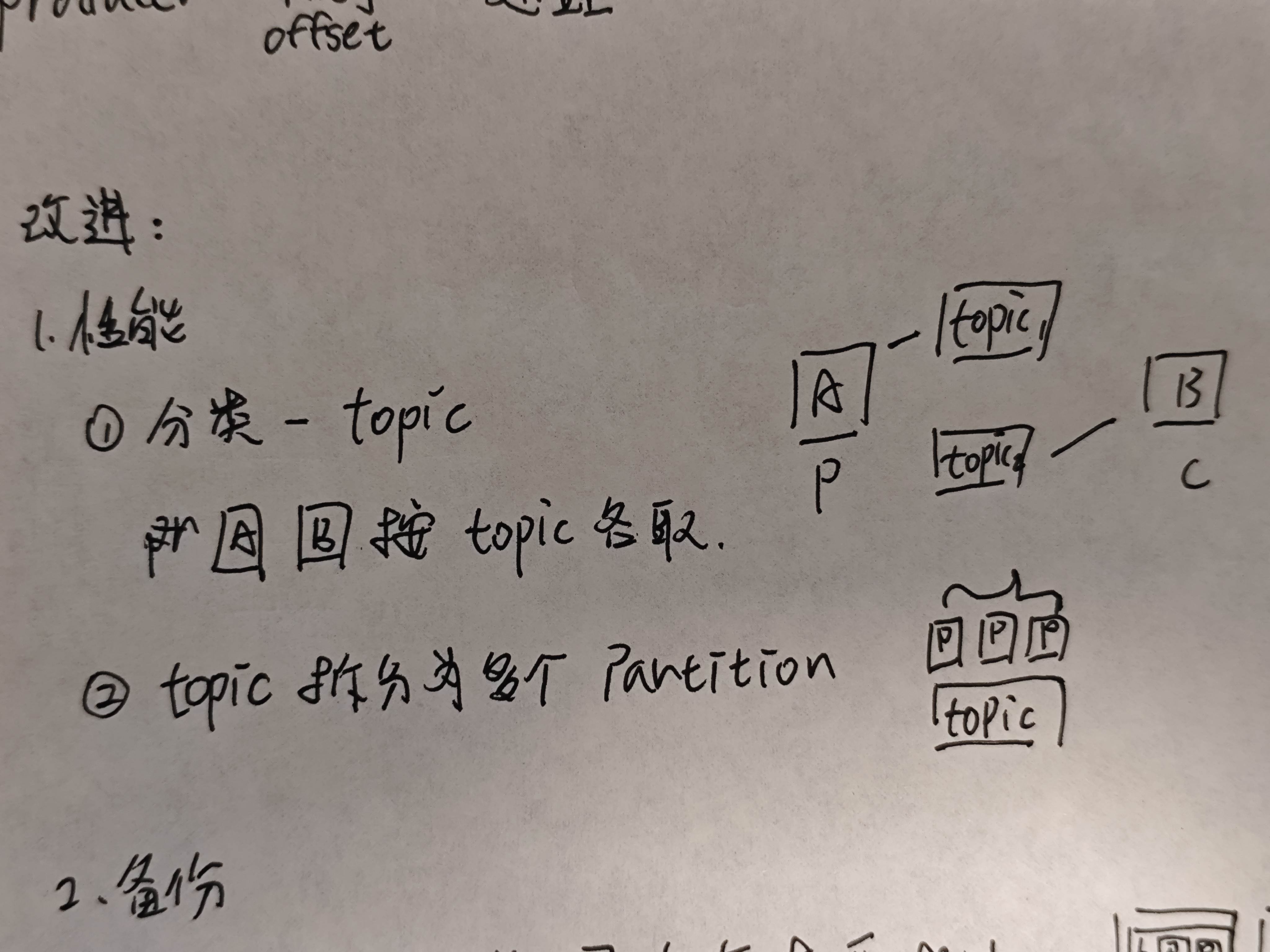
2.备份
对数据进行分类后,我们就可以对数据的完整性进行保障。
1. 异步同步
一般情况下,不做任何保证的broker可能会在机器宕机时丢失所有数据。 于是我们把partition复制成两份,一份叫做leader,复制处理信息队列,另一个叫folllower,同步leader的数据,并把他们分散在不同的broker中。 当一个leader挂掉了,follower会选举出新的leader。
听起来和磁盘阵列的数据备份原理有点相似。
2. 持久化
假设遇到了极端的情况,如所有的broker都挂掉了,那怎么办呢? 为了避免这种情况的出现,broker会定期将数据存储到磁盘中,保证数据的可用性。当磁盘太满时,可以设定相应的保留策略来清理数据。(当数据超过一定大小,放置超过多长时间就被清除) 
图片上边关于异步同步的部分有点出错,以此笔记为准
4. 其他
1. commsummer组
commsumme组可以从指定的offser序号开始处理,彼此之间相互不打搅。
2. zookeeper
定期和broker通信,判断和维护kafka的状态