本文最后更新于 145 天前,其中的信息可能已经有所发展或是发生改变。
实验步骤
可以联系pandas脏数据方法篇
1. 导入
做的实验是基于pandas的基础,所以要先引入包。
import pandas as pd使用下列方法导入表格:
pd.read_excel('XXX.xlsx',dtype = 'object')
-
初步的看一下表头
- 由于表格里边的类型繁多,所以使用
object来包罗万象
- 由于表格里边的类型繁多,所以使用
-
有数据,有表头,可以使用
read_exel('文件名')导入- csv就是
read_csv('文件名')
- csv就是
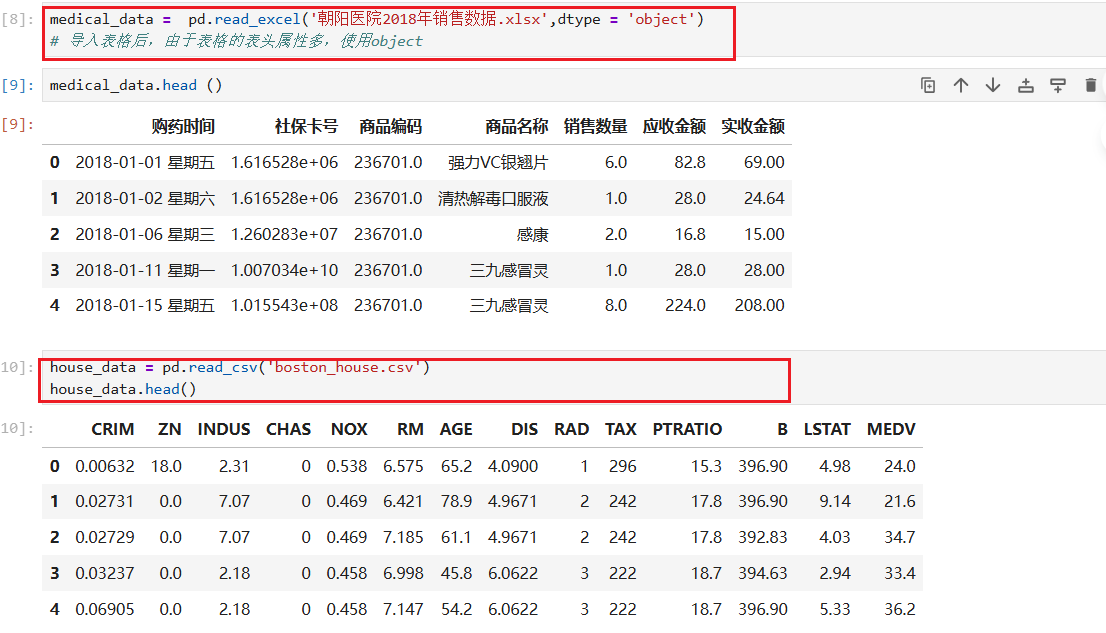
如果发现没有表头,需要:
adult_data = pd.read_csv('adult.data',header=None)
adult_data.head()标注header=None让系统知道第一行不是表头而是数据
2. 查看
[名字].head([看前几行的数据])- 检查数据是否有问题
3. 探查
[文件名].info()
- 查看整体信息
- 然后开始排错
4. 排错
1. 空值
print(文件名.isna().sum())
isna(): 有没有空值sum():把输出结果集合
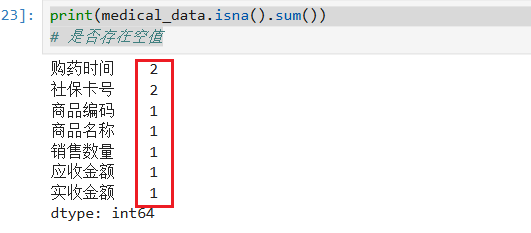
出现数字即为存在空值
2. 异常值
[文件名].describe()
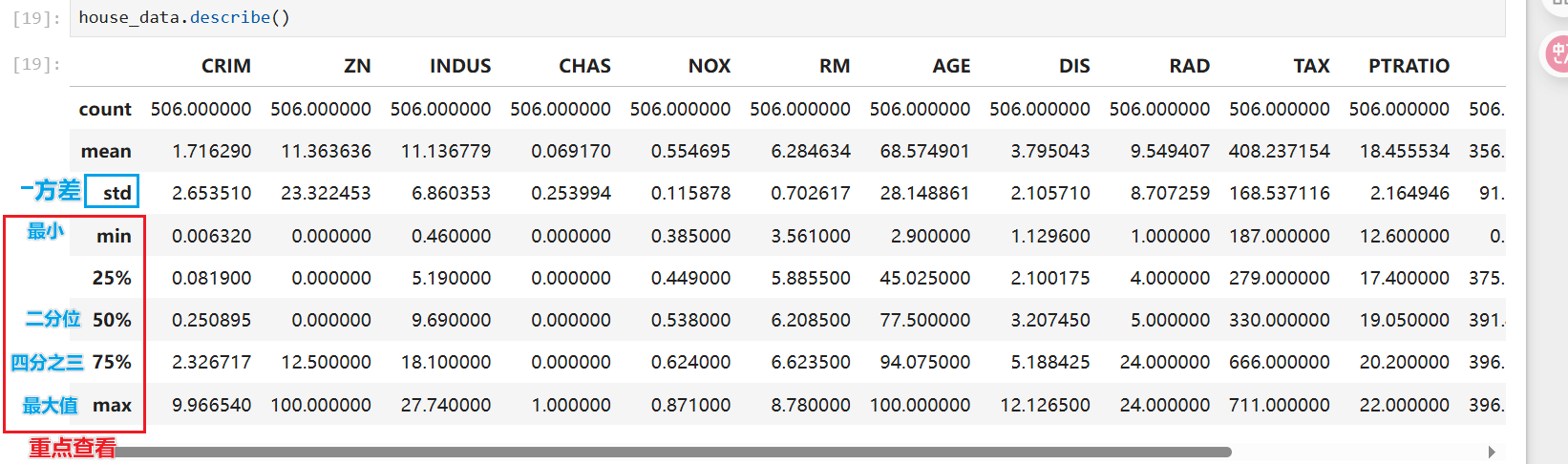
查看后需要自己观察数据,找出一场所在
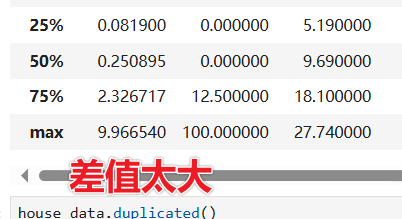
如上图,错误原因为四分之一,二分之一,四分之三之间差值过大,加起来也达不到max值,所以即为出现异常值。
- 属性
- 把属性存储在adult_data里
- 创建列的列表
- 把列表赋给列的索引
排错