本文最后更新于 294 天前,其中的信息可能已经有所发展或是发生改变。
1. 什么是redis,使用场景如何?
一个大型公司对外提供一些查询功能(如12306的抢票,618的搜索查询),数据库可能会没办法负担得起这么多request。 在这个时候,我们就可以加入中间件redis来为mysql分担流量。
2.原理
1. 本地缓存
mysql的数据存储在磁盘上,这样做的好处是比较稳定,坏处就是查询的速度很慢。redis把数据存储在内存上,这样查找的速度就会快很多。 只有我大概能看懂的架构图如下: 
redis把mysql存在内存的数据拷贝过来到磁盘里,使得用户在查询时直接调用redis储存在内存的数据。如果用户查询时redis没有找到,就回去磁盘下查找与之相关的数据,如果查到了,在提供给用户的同时顺带将其存储在内存中。
此外,redis存储数据的模式是键值对,但是支持多种数据的拓展:如list,set去重,zset排行榜的数据
2. 远程缓存
远程缓存时可能会同时处理多台数据库的服务,redis将其浓缩成一个单线程,一起处理。 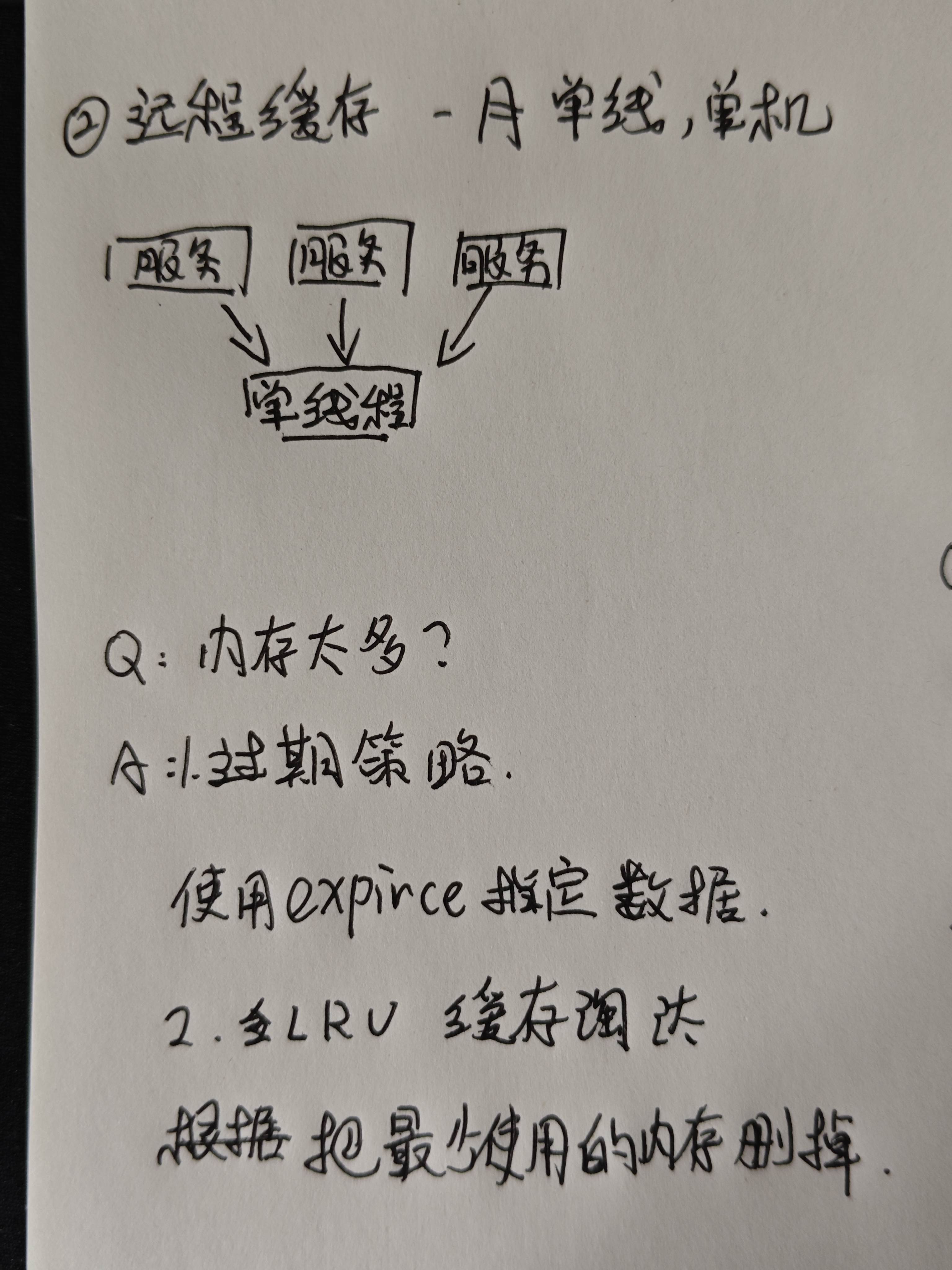
3.缓存策略
当内存过多时,redis也会炸,但是炸了就不好了,这又不是炸鱼,但时候提供给用户的服务怎么办?因此redis也具备与缓存相关的策略。
1. 过期策略
使用expirece命令查询哪些数据可以被删除了
2. LRU缓存淘汰机制
使用算法,把最少使用的内存给删掉。
4. 持久化
是帮数据库减少压力了,但是你的数据怎么保障呢?如果我已关机,啪的一下数据全没了可不就西提沃克,背着工位上的行李漫游城市了吗 因此也有相应的持久化策略。
1. 异步同步
redis会把内存上的数据生成RDB快照后压缩保持到磁盘里,就像使用VM时担心后续实验出错,自己先保存快照一样。
2. AOF机制
AOF机制就是在你向redis写入数据时,顺手将数据同步到mysql里。